Pythonのscikit-learnで行う「分類」
執筆者:南波真之
※本記事は吉政創成株式会社「Python学習とキャリアアップ」より寄稿されたコラムとなります。

皆さん、こんにちは。南波真之(なんばさねゆき)と申します。
私はエンジニアではない文系の人間ですが、Pythonの可能性やデータ分析を使った仕事に興味があります。
前回はscikit-learnの前処理について取り上げてきました。データ分析を行う際、いきなり分析はできません。まずはあるデータを正しく分析できるように前処理を行う必要があります。
さて今回は、scikit-learnの続きです。データ分析の1つの方法に「分類」があります。今回はこの「分類」についての概要を学習しましたので記事にしていきます。私が勉強しているPythonによるあたらしいデータ分析の教科書(翔泳社)の、P223.〜P.226の部分です。
データ分析の「分類」とは
データ分析における「分類」は、データの「クラス」を予測して分けるタスクのことです。どういうことかというと、例えば過去の購入商品ともとにして、顧客が新製品を購入する(可能性がある)かしない(可能性がある)かを分類するケースと考えるとわかりやすいのではないでしょうか。
この分類は、教師あり学習の典型的なタスクで、クラスが既知のデータを教師として利用し、各データをクラスに振り分けるモデルを学習するため、教師という正解のデータがはっきりしている際に利用するのに適しています。
この分類という分析方法ですが、アルゴリズムとして代表的なものをいくつか紹介します。
- サポートベクタマシン
- 決定木
- ランダムフォレスト
今回は詳しく取り上げないのですが、どれも重要な考え方になっています。
さて、それでは分類モデル構築の流れに移ります。
分類モデルの構築
分類モデルの構築を行うには以下の手順を行います。
- 手元のデータセットを「学習データセット」と「テストデータセット」に分ける
- 学習データセットを用いて分類モデルを構築 = 学習
- 構築したモデルのテストデータセットに対する予測を行い、未知のデータに対する対応能力 = 汎化能力 を評価する
今あるデータセットに対して、まずは学習用とテスト用に分けます。そこから、学習用の方を使って学習をさせて分類モデルを作り、テスト用のデータにそのモデルを適用して予測結果を出すという流れです。
1回だけやるのではなく。学習データセットとテストデータセットの分割を繰り返して、モデルの構築と評価を複数回行う方法を交差検証と言い、こちらも重要です。
今回私達が学習している scikit-learnの場合は、学習はfitメソッド、予測はpredictメソッドを使います。
それでは実際にIrisデータセットを使ってこの分類を試してみます。このIrisデータセットは、scikit-learnに入っているデータで、アヤメという花の情報がたくさん入っています。このデータを使って分類をやってみます。
from sklearn.datasets import load_iris
Irisデータセットの読み込み
iris = load_iris()
iris.dataには、データが入る
iris.targetには、正解ラベル(最終的に予測して導き出したい値)が入る
X, y = iris.data, iris.target
先頭5行を表示
print('X:')
print(X[:5, :])
print('y:')
print(y[:5])
↓(出力結果)
X:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
y:
[0 0 0 0 0]
出力結果は、先頭の5つだけをとっているのですが、それぞれ半角スペースで分けられた4つのデータがあります。左から、がくの長さ、がくの幅、花びらの長さ、花びらの幅のデータです。変数Xの方に説明変数(特徴量)と呼ばれるこれらのデータが格納されています。そして変数yの方は、アヤメの種類を表す目的変数が格納されています。
データが用意できましたので、ここからはtrain_test_split関数を使ってデータを分けて分析をやっていきます。
# 学習データとテストデータに分割
# test_size=0.3はテストデータの割合30%の意味
# random_state=123はシード値
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
↓(出力結果)
(105, 4)
(45, 4)
(105,)
(45,)
この結果は、以下の意味になります。
- 特徴量の変数X_trainのサイズは 105×4行列
- テストデータの変数X_testのサイズは 45×4行列
- 学習データセットが全部で150の内の105なので、全体の70%
- テストデータセットが全部で150の内の45なので、残りの30%
- 目的変数のy_trainのサイズは105
- 目的変数のy_testのサイズは45
分類モデルを評価する
ここまでで構築してきた分類モデルを評価してデータを出していきます。分類の精度指標は多く存在していますので、その中からいくつか出していきます。
- 正解率(Accuracy)
- 適合率(Precision)
- 再現率(Recall)
- 特異度(Specificity)
- F値(F-score)
サポートベクターマシン(SVM)という機械学習のアルゴリズムと分類のためのモジュールを使って表示していきます。
from sklearn.svm import SVC
SVMのインスタンス化
svc = SVC()
SVMで学習
svc.fit(X_train, y_train)
テストデータセットの予測
y_pred = svc.predict(X_test)
分類のためのモジュールをインポート
from sklearn.metrics import classification_report
分類して表示
print(classification_report(y_test, y_pred))
すると、出力結果はこのようになりました。
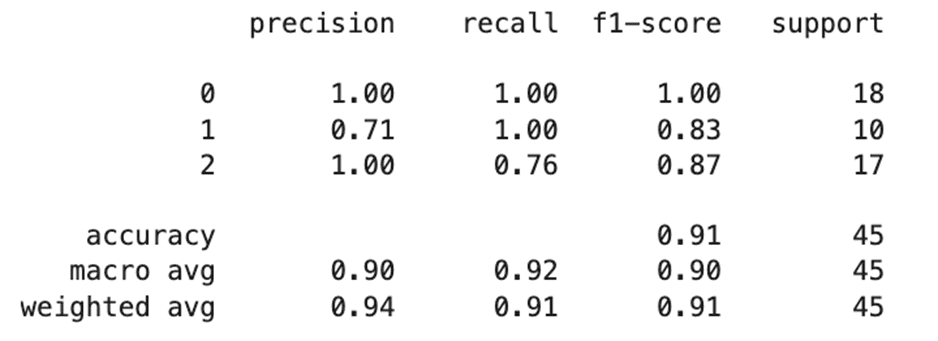
縦(行ラベル)の0, 1, 2はクラスのことです。そしてaccuracyは正解率、macro avgはマクロ平均(各ラベルの評価値を合計して平均を出した数)、weighted avgは重み付き平均(各ラベルの評価値とそのラベル数の積を合計して,平均を出した数)となります。
横(列ラベル)を見ると、precisionは適合率、recallは再現率、f1-scoreはF値、supportはデータの件数となります。
その前提で確認をすると、クラス0は適合率、再現率、F値がどれも1.00で、データ数は18ということが分かります。どれも1.00だと面白くないので、クラス2を見てみます。
すると適合率は0.71、再現率は1.00、F値は0.83で、データ数は10となっています。
適合率とは、陽性(正しい)と予測したもののうち、実際に陽性(正しい)であるものの割合のことですので、この数字が「1に近い = 高い」と正しいと予測したとおりに実際も正しかったということになります。しかし「1から遠い = 低い」場合には正しいと予測した結果外れたケースが多かったということになりますので、間違って正しいと判断してしまうことを避けたい場合にチェックするのに適しています。
再現率は、実際に陽性(正しい)であるもののうち、正しく陽性(正しい)と予測できたものの割合のことです。適合率の考え方と対照的なのが分かります。つまり、間違って正しくないと判断しては困る場合にチェックするのに適しています。
そしてF値は適合率と再現率の調和平均ですのでバランスよくこれらの評価ができるものということになります。クラス1については、適合率が少し低いため、正しいと予測していたが間違っていたケースがそこそこ発生したということになります。
サポートベクターマシンやこの評価の考え方については、次回以降でも取り上げていきます。
データ分析をscikit-learnで実施する
今回は「分類」というデータ分析の方法を取るための概要と、実際にscikit-learnを使っての分類を実施してみました。
データ分析の知見とscikit-learnの知識が必要になる部分なので習得はとても大変だと感じましたが、scikit-learnは様々なデータ分析を実現できる道具は揃っているため、あとは私達次第です。しっかり学習していきたいと思いました。
インターネット・アカデミーは、Python講座が充実しています。Python認定スクールにもなっているため質の高い知識を得ることができ、基礎学習の先にあるそれぞれの目標を目指していくためには良い場所となります。ご興味ある方は各講座のページを覗いてみてください。
南波真之
デジタル人材育成・助成金のお役立ち資料をダウンロード

デジタル人材育成や助成金活用のお役立ち資料などをまとめてダウンロードしていただけます。コンサルタントへの無料相談をご希望の方はこちらからお問い合わせください。
- DX人材の育成&事例紹介 リスキリングのロードマップ付き
- デジタル人材育成に使える助成金制度
- デジタルスキル標準 役割別おすすめ講座
