Pandasで統計データを出してみる
執筆者:南波真之
※本記事は吉政創成株式会社「Python学習とキャリアアップ」より寄稿されたコラムとなります。

皆さん、こんにちは。
南波真之(なんばさねゆき)と申します。
前回はPythonでのデータ分析を容易にする機能のライブラリであるpandasについて取り上げてきました。pandasを使い、外部のデータを読み込んでDataFrameにて表示させる、ファイルの形で書き出し、データの編集などを行うことでより実務に近いイメージでpandasを活用できることを学びました。ご興味ある方はぜひご覧ください。
さて、今回はpandas(パンダス)です。私が勉強しているPythonによるあたらしいデータ分析の教科書(翔泳社)の、P169.〜P.174の部分です。pandasを使い、データの基礎統計量を表現することで、そのデータの意味を把握するという部分について学習してみました。
基礎統計量(最大、最小、平均、中央、標準偏差、件数)
pandasとは、Pythonのデータ分析を容易にする機能のライブラリで、データ分析のツールとしてはとてもよく使われているものです。データ分析をする際には、手元にあるデータをまず整理するところから始まります。これを前処理と呼ぶこともありますがこのデータ整理で大きく効力を発揮します。pandasは、NumPyを基盤にして2つのデータ型があります。1次元データのSeries(シリーズ)と2次元データのDataFrame(データフレーム)です。
今回はpandasを使い外部からExcelファイルを読み込み、そのデータを使って基礎統計量を見ていきます。基礎統計量とは、最大値や平均値、標準偏差などの統計において一般的に使われるデータのことです。どれだけたくさんのデータがあってもそれを使うことができなければ意味がありませんので、学習の必須項目といえます。
例えば、1,000件のデータの平均値、中央値を表示させることでデータの傾向を見る、該当の条件のデータが何件あるのかを把握する、などが考えられます。
まずは、dataディレクトリの中にある対象のExcelファイルを読み込み、表示させてみます。変数dfに値を入れています。
import pandas as pd
df = pd.read_excel("data/sampleデータベース.xlsx")
df
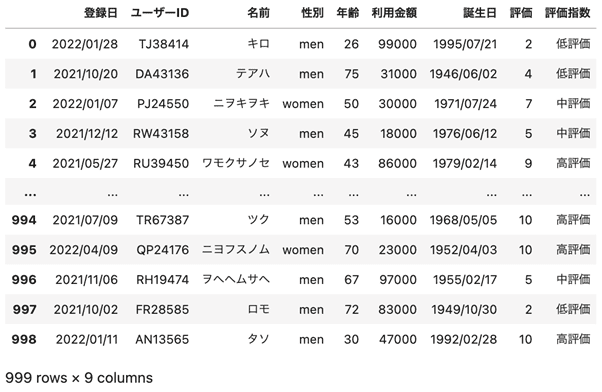
出力は、このようになりました。
それでは、このデータを使って基礎統計量を出してみます。
1.最大値
最大値は、文字通りでmaxを使います。例えば「年齢」の最大値を確認します。locは行名、列名の指定で特定の値を抽出します。: は全てという意味になります。
【出力結果】
82
つまり、82歳がデータの中で一番高齢ということがわかりました。
2.最小値
最小値も文字通りでminを使います。「年齢」の最小値を確認します。
【出力結果】
22
つまり、22歳がデータの中で一番若いということがわかりました。
3.最頻値
対象のデータの最頻値を確認する事もできます。最頻値とは、データ上で出てくる頻度が一番高い数値のことです。modeを使います。「年齢」の最頻値を確認します。
【出力結果】
0 81
Name: 年齢, dtype: int64
81が最頻値ということでこのデータの対象は高齢者が最頻値になることがわかりました。出力にある0は、インデックスの番号ですので最頻値の値としては81のみが出力されました。
4.平均値
平均はもしかすると一番馴染みがある統計量かもしれません。「年齢」の平均値を確認します。
【出力結果】
52.13613613613614
平均を取ると、52歳が平均値であることがわかります。このデータは平均値で見ると若者が少なく、中高年のデータが多くあるのではないか、ということがわかりました。
5.中央値
平均とセットになる統計量として、中央値があります。中央値は平均とは異なりデータを並べたときに一番真ん中に来るデータを表現します。こちらも、「年齢」で中央値を確認します。
【出力結果】
52.0
中央値が52歳であることがわかりました。平均値とほぼ合致しましたね。
中央値と平均値は一般的には一致せず、データの分布が対象の場合に一致するので今回はデータの分布がきれいに対象になっていることがわかります。
6.標準偏差
続いて、標準偏差です。統計を学んでいくと必ず出てくるものですね。これは、データが平均値の周辺でどれくらいばらついているのかを見るものです。
例えば平均値が同じ52のデータでも、52の周辺にデータが集まっているのか、20や80など様々なデータが存在しているのかでは意味が全く異なります。つまり、標準偏差の値が大きいと、データがばらついていることになります。
早速「年齢」で標準偏差を確認します。標準偏差はStandard Deviationで.stdを使います。
【出力結果】
17.586359645379677
標準偏差が17.586...であることがわかりました。平均値からどれくらいデータがばらついているのかという基準ですので、平均値の52歳からプラスマイナス17.58歳のところに多くのデータがあるということになります。おおよそ、平均値からプラスマイナス標準偏差1個分の範囲にあるデータが全体の約68%、プラスマイナス標準偏差2個分の範囲にあるデータが全体の約95%と言われています。
7.データの個数
何らかの条件のデータがいくつ存在しているのかを確認することもあります。例えば、年齢が45歳以上のデータの個数を確認します。
【出力結果】
登録日 630
ユーザーID 630
名前 630
性別 630
年齢 630
利用金額 630
誕生日 630
評価 630
評価指数 630
dtype: int64
各カラムで出してしまったので同じ数字が出ていますが、45歳以上のデータは630個あることがわかりました。
8.全て
ここまでは個別の基礎統計量を出力してきましたが、実は一発で全てを表示させることもできます。その際は、describeを使います。
【出力結果】
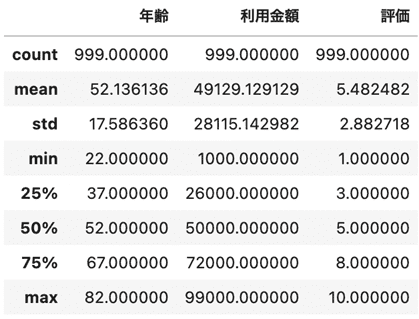
今まで説明してきた基礎統計量に加えて、全体の4分の1にあたる25%や全体の4分の3にあたる75%の確認もできます。中央値(median)は50%のところです。
9.番外編:相関係数
相関係数とは、2つのデータの相関関係(どれだけ関連しているのか)の度合いを示します。例えば運動部に入っている生徒の数学のテストの点数が高いということの相関関係があるのか、など相関関係はデータを見る上でとても重要です。
相関係数は、1に近いと正の相関(1つ目のデータが増加すると2つ目のデータも増加する傾向がある)、-1に近いと負の相関(1つ目のデータが減少すると2つ目のデータも減少する傾向がある)、0に近いと相関がないということになります。
早速pandasで出力させてみます。corrを使い、これはcorrelation(相関)のことです。
【出力結果】
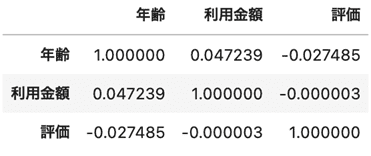
例えば年齢と利用金額の相関係数は、0.047239と出ました。正の相関が少しありそうです。逆に利用料金と評価の相関係数は-0.000003と出ていますので、負の相関ではありますが限りなく0に近いので相関はないと判断できます。
DataFrameを活用した統計量の把握を使っていこう
今回はpandasを使い、基礎統計量を出力させる部分を取り上げてみました。
こういったデータの分析ができてくると学習が楽しくなってきます。サンプルデータでも良いので、一度Pythonとpandasを使い基礎統計量を出してみると面白くなり、統計の知識も自ずと理解できるようになりますのでおすすめです。
Pythonやpandasはあくまでツールに過ぎません。一番大事なことはこのツールを使って何がしたいか、何を知りたいかです。この部分を忘れずに私も勉強を進めていきたいと思っています。
import pandas as pd
df = pd.read_excel("data/sampleデータベース.xlsx")
## 出力
df
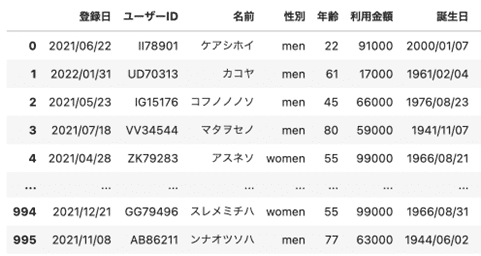
出力はこのようになります。
df.to_pickle("data/sampleデータベース.pickle")
## 保存した.pickleのDataFrameを読み込み、dfに代入
df = pd.read_pickle("data/sampleデータベース.pickle")
## 出力
df
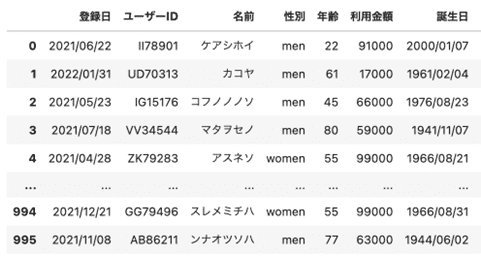
出力はこのようになります。
同じものが出力されました。
このように、pickleに保存をしておくことでDataFrameをそのままファイルとして保存して再利用できるようになります。
pandasでのデータの編集
pandasを使ったデータの編集もよく使われます。例えば、データの抽出、並べ替え、削除などです。大量のデータが単にDataFrameになっているというのはもったいないので、自分が見たいデータだけを取り出して手を加えていくようにしていきます。
1つ目は、データの抽出です。特定の年齢帯の人だけを抽出したいという事はあると思います。
df_selected = df[df["年齢"] <= 30]
df_selected
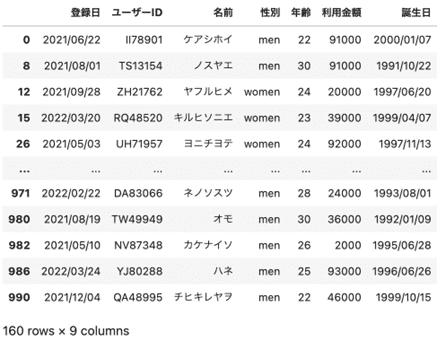
出力はこのようになり、年齢が30歳以下の人だけがDataFrameとして出力されました。
2つ目は、条件を増やしたデータの抽出です。年齢と利用金額の2つを基準に抽出した上でその関係性を見るということも分析では行うこともあります。
## queryメソッドを使う
df.query('年齢 <= 30 and 利用金額 >= 90000')
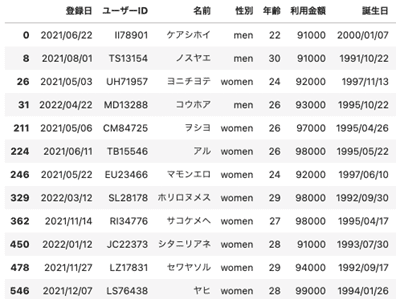
出力は、こうなります。問題なく指定した条件のデータのみが出力されています。
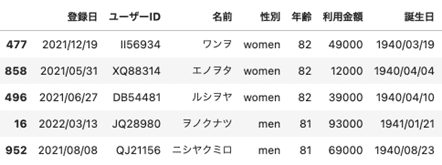
その他、データの並べ替えは以下のように行います。年齢が大きい順に並べていますが、小さい順に並べたい場合は ascending=True とすれば並ぶようになります。
df.sort_values(by="年齢", ascending=False).head()
更に、表データを全て使う必要がない場合に、余分なカラムを削除するということも可能です。例では、「年齢」のカラムを削除しています。
df = df.drop("年齢", axis=1)
出力結果を見ると「年齢」が消えてしまっていますね。このように、DataFrameを様々自分の望ましい形にした上でデータ分析をしていくというのが基本的な流れとなってきます。
DataFrameを活用することで
今回は、pandasのDataFrameのデータの読み込みから書き込み、そして編集というところを取り上げてきました。
Pythonにおけるデータ分析でpandasは使われることが多く、身につけておきたい知識の1つです。理解すべき項目も多いですが、細かい部分を理解しておくことで応用が効くようになると思いますので、頑張りましょう。
インターネット・アカデミーは、Python講座が充実しています。Python認定スクールにもなっているため質の高い知識を得ることができ、基礎学習の先にあるそれぞれの目標を目指していくためには良い場所となります。ご興味ある方は各講座のページを覗いてみてください。
南波真之

デジタル人材育成・助成金のお役立ち資料をダウンロード

デジタル人材育成や助成金活用のお役立ち資料などをまとめてダウンロードしていただけます。コンサルタントへの無料相談をご希望の方はこちらからお問い合わせください。
- DX人材の育成&事例紹介 リスキリングのロードマップ付き
- デジタル人材育成に使える助成金制度
- デジタルスキル標準 役割別おすすめ講座
