pandasのDataFrameの基礎を理解する
執筆者:南波真之
※本記事は吉政創成株式会社「Python学習とキャリアアップ」より寄稿されたコラムとなります。

皆さん、こんにちは。
南波真之(なんばさねゆき)と申します。
私はエンジニアではない文系の人間ですが、Pythonの可能性やデータ分析を使った仕事に興味があります。
前回はPythonの標準機能に追加しての数値計算や多次元配列を利用できるNumPyの機能であるユニバーサルファンクションとブロードキャストについて取り上げてきました。ユニバーサルファンクションは一括で配列内のデータを変換してくれる機能、ブロードキャストは配列の内部データに直接演算を行える機能です。
さて、今回はpandas(パンダス)です。私が勉強しているPythonによるあたらしいデータ分析の教科書(翔泳社)の、P133.〜P.143の部分にある、pandasのDataFrame(データフレーム)について学習してみました。
pandasとは?
pandasとは、Pythonでのデータ分析を容易にするような機能のライブラリです。データ分析のツールとしてはとてもよく使われているものです。
データ分析をする際には、手元にあるデータをまず整理するところから始まります。これを前処理と呼ぶこともありますがこのデータ整理で大きく効力を発揮します。
pandasは、NumPyを基盤にして2つのデータ型があります。1次元データのSeries(シリーズ)と2次元データのDataFrame(データフレーム)です。今回はよく使われるDataFrameについて学習します。
初めてpandasを使う場合は、まずpipを使ってインストールするところから始めます。
pandasを使うには NumPy同様に以下のようにインポートを行います。
DataFrame(データフレーム)
DataFrameは2次元のラベル付きのデータ構造のことです。表のような形式になるため、ExcelやSpreadsheetのようなイメージが作れます。
まずは例を見てみます。
df = pd.DataFrame({
# ディクショナリ型でデータを入れてみる
'名前' :['田中一郎', '山田次郎', '高橋三郎'],
'社員ID' : [32, 103, 3],
'役割' : ['営業本部長', 'マーケティング部', 'COO'],
'趣味' : ['マラソン', 'ソロキャンプ', '海外旅行']
})
df

この出力結果はこちらです。
この表の0~2の縦部分をindex(インデックス)、名前〜趣味までの横のことをcolumns(カラム)といい、知っておくと便利です。
それは、様々な記述方法において、indexとcolumnsを指定することができるからです。
1.上記のソースコードにてindexを編集する
-
df = pd.DataFrame({
# ディクショナリ型で入れてみる
"名前" :["田中一郎", "山田次郎", "高橋三郎"],
"社員ID" : [32, 103, 3],
"役割" : ["営業本部長", "マーケティング部", "COO"],
"趣味" : ["マラソン", "ソロキャンプ", "海外旅行"]
})
df.index = ["001", "002", "003"]
df -

2.リストを使って表現
-
df = pd.DataFrame([["田中一郎", 32, "営業本部長", "マラソン"],
["山田次郎", 103, "マーケティング部", "ソロキャンプ"],
["高橋三郎", 3, "COO", "海外旅行"]])
df.index = ["001", "002", "003"]
df.columns = ["名前", "社員ID", "役割", "趣味"]
df -

このように、indexとcolumnsは指定できるためよりわかりやすく表示を編集することができます。
pandasのデータ型 object型について
先程のソースコードで出力されたデータの中で、社員IDだけが整数(int型)で、その他がobject型という扱いになります。それを確認してみます。
df = pd.DataFrame({
# ディクショナリ型で入れてみる
'名前' :['田中一郎', '山田次郎', '高橋三郎'],
'社員ID' : [32, 103, 3],
'役割' : ['営業本部長', 'マーケティング部', 'COO'],
'趣味' : ['マラソン', 'ソロキャンプ', '海外旅行']
})
print(df.dtypes)
データタイプを見てみます。
社員ID int64
役割 object
趣味 object
dtype: object
整数の社員IDがint型、それ以外がobject型になっています。
pandasは列ごとにデータ型を持っており、これはpandas特有のデータ型です。文字列を含むデータは、object型に指定されます。1つの列に整数と文字列が混在している場合もobject型になります。
データの出力指定
また、今回はデータが少ないので必要ありませんでしたが、データ量が多い場合は最初の5行だけ、最後の5行だけを表示させるということもよくあります。
例えば、このようなデータがあったとします。
import pandas as pd
df = pd.DataFrame(np.arange(100).reshape((25, 4)))
df
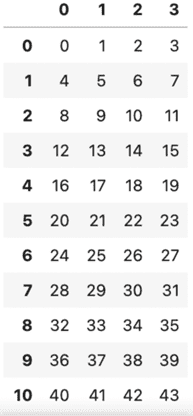
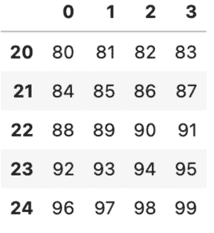
出力結果の一部を紹介しますが、このようにデータ100個が25行4列で出力されます。
ただし、これでは見るのが大変ですので df.head() や df.tail() を使って最初もしくは最後の5行を表示させることができます。
-
df.head()
-

-
df.tail()
-
データの取り出し方法
特定のデータのみを出力して取り出したいということはよくあります。こういった場合は、indexとcolumnsを指定して取り出します。
df.loc[取り出したい行, 取り出したい列]
と記述するのですが、こうなります。
-
df.loc[:, ["名前", "役割"]]
-

: はすべてという意味ですのでindex(行)はすべて、columns(列)は名前と役割のところだけを取り出しました。
ちなみに、似たやり方でilocというのもあり、これはindex番号とcolumns番号を指定して取り出すというものです。プログラムの世界では最初は0から始まりますので、例えば以下のように取り出すとどういったデータになりそうでしょうか。

答えは、こちらです。
このような形で、pandasのDataFrameを理解することでデータの整理や表現の仕方が大きく幅ができるようになります。
DataFrameを活用することで
今回は、pandasのDataFrameをメインに書いてきました。
Pythonにおけるデータ分析でpandasは使われることが多く、身につけておきたい知識の1つです。
理解すべき項目も多いですが、細かい部分を理解しておくことで応用が効くようになると思いますので、頑張りましょう。
インターネット・アカデミーは、Python講座が充実しています。Python認定スクールにもなっているため質の高い知識を得ることができ、基礎学習の先にあるそれぞれの目標を目指していくためには良い場所となります。ご興味ある方は各講座のページを覗いてみてください。
南波真之

デジタル人材育成・助成金のお役立ち資料をダウンロード

デジタル人材育成や助成金活用のお役立ち資料などをまとめてダウンロードしていただけます。コンサルタントへの無料相談をご希望の方はこちらからお問い合わせください。
- DX人材の育成&事例紹介 リスキリングのロードマップ付き
- デジタル人材育成に使える助成金制度
- デジタルスキル標準 役割別おすすめ講座
